Binary Function Similarity Detection: A Practical Introduction
2163 Words, est. 9min
Reverse engineering a binary is slow. For a trained analyst, a single complex binary can take hundreds of hours to fully understand. That number is not an exaggeration.
You are working without source code, often without symbols that would tell you a function’s name or the types of its arguments, and with only a rough sense of what the software
is even supposed to do. The job is fundamentally about separating signal from noise, and most functions in a binary are noise. printfs, mallocs, and strcpys, oh my!.
It’s boilerplate as far as the eye can see. An experienced analyst learns to recognize these on sight and skip them, but that pattern-matching takes time to develop, and requires
combing through the whole binary anyway. Skilled reverse engineers are expensive and in short supply. What’s an intelligence agency to do?
Malware is also more predictable than you might think. Most malware authors are not cryptographers inventing new primitives from scratch. They are engineers working desperately to drain your most annoying friend’s bitcoin wallet so their families don’t get sent to a gulag. They iterate on what they know already works. A ransomware family that evades detection today will be tweaked slightly next month when it stops working, not thrown out and rewritten. The core logic is reused. The structure is reused. Often, specific functions are reused verbatim.
When you’re operating at a function level of granularity, there’s more overlap between malware and goodware than you might think. Stuff malware does like opening sockets, creating mutexes, or encrypting files, is stuff regular files do all the time. An analyst separates the good from bad only by looking at what the functions do in concert.
Binary function similarity detection (BFSD) is the idea that we can automate the recognition of “I have seen this function before.” Given a function from an unknown binary, a similarity system answers: what known functions does this most closely resemble, and from what binaries did they come? The payoff is significant. An analyst who can instantly label 80% of a binary’s functions as known-benign or known-malicious is an analyst who can focus on the 20% that actually matters.
What a Similarity System Looks Like
At a high level, every BFSD system has three components (or maybe four, depending on how you count).
The first is a known function database. This whole exercise is useless without something to compare against. In practice this means a large indexed collection of functions with known provenance: open source libraries, malware samples, compiler boilerplate. You name it. Throw it on the pile. The query is “find me the nearest neighbors to this function in the database.”. How do you decide what those are?
That’s where the similarity model comes in. It takes two functions and produces a score. This is the part that gets academics hot and bothered, and its where most of the energy
in the field is right now. It might be a hand-crafted heuristic (like Ghidra’s BSim), a classical embedding model, or a transformer trained on millions of function pairs. Think about
it like a recommendation algorithm, except instead of showing you woodworking videos or new music, it shows you known malware or a hundred thousand copies of __raise_security_token.
An important and related part is the representation layer that converts the functions into something a model can reason about. This might be just the raw bytes, disassembly, control flow graphs, intermediate representations, or decompiled pseudocode. The choice here matters enormously, and I will come back to it.
The final part is the interface, which highlights functions that don’t match anything in the database (the kind of thing an analyst would be very interested in) or shows useful information about the ones that do match. This is the part that the analyst actually interacts with, and can make or break the system. Trust is paramount. In my experience, analysts develop their own customized workflows. This gives them an understanding about how their tools work, and whether they work well. Many have a distrust of machine learning based solutions. I could go into why I think that is, but suffice to say: presentation matters.
The Representation Cone
Here is where I want to spend some time, because I think the framing most people use for this problem is wrong, especially in academia.
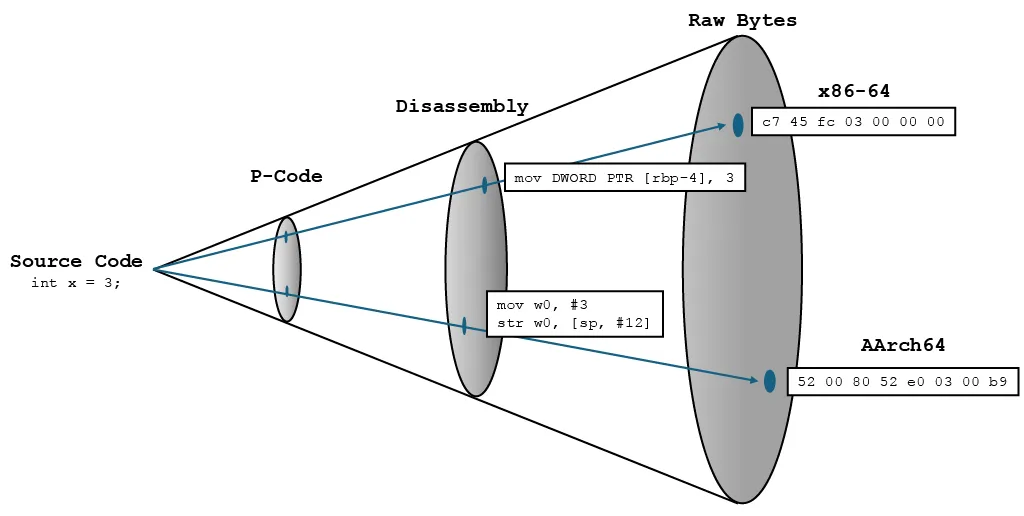
Consider the diagram above from my notes. At one end you have source code. At the other, raw machine bytes. Everything in between is a “lifted” representation: disassembly, p-code, or fully decompiled C-like pseudocode. These representations form a kind of cone, with the original source at a single point from which all possible representations flare out. Moving up the cone means more semantic structure, and better human readability.
Did you catch that? Better human readability. The intuition behind using lifted representations seems sound. If two functions do the same thing but were compiled for different architectures, their bytes look nothing alike to us. But their disassembly starts to become interpretable if you squint. Their p-code (which I haven’t shown on the cone) converges even further. The task seems easier.
The catch is that you have not actually made the problem any easier. Not for the model, anyway.
These lifted representations were designed as a tool for human cognition. Disassembly exists because humans cannot read machine code fluently. Decompilation exists because humans cannot read disassembly fluently. Each step up the cone is optimized for reducing working memory load and leveraging the years of context a trained analyst brings to the table. That is a worthy goal. It is just not the same goal as making a machine learning task easier.
A model does not experience scrutability. It does not benefit from the fact that mov rax, 0x1 is easier for you to parse than 48 c7 c0 01 00 00 00. It only sees a sequence of tokens.
The question is whether the statistical structure of those tokens is easier to learn from, given your model’s architecture, your training data, and your goal. Human readability and
model learnability are just vastly different optimization targets. They can coincide, but assume so only at your own peril.
There is actually a reasonable argument that raw bytes are a more natural input in function similarity anyway. The structure is fixed and regular. A byte is a byte is a byte, and there are only 256 of them. Sure, a byte could
be an instruction in one place, a memory address in another, and the pixel value of an image in another, but that’s okay. These are easy relationships for a model to learn. On the other hand, disassembly introduces
a larger vocabulary of tokens that encode architecture-specific mnemonics. mov in x86 and ldr in AArch64 are semantically close but will inevitably be given
different token representations (unless you’re using some handcrafted approach, which… why use machine learning at all?). A model trained on raw bytes has to learn these bridges anyway.
It is not obvious that doing this over disassembly is any easier.
None of this means lifted representations never help. Empirically, some do, on some tasks, with some architectures. Function similarity is not the only machine learning task in the cybersecurity world. The point is that the justification usually given, that disassembly is “more meaningful,” smuggles in an assumption about what meaningful means. Meaningful to whom?
That assumption has practical consequences, which brings me to the four problems I actually have with lifted representation methods.
Four Problems with Lifted Representations
Two of these are about research methodology. Two are about what happens when you actually try to bundle this into a product and hand it off to an analyst.
Reproducibility in Function Similarity is completely broken. Academic papers on BFSD are almost universally evaluated on top of a specific disassembler for each method, often a specific version with specific settings, running a specific script written by the researcher (or a researcher’s sleep-deprived grad student). Different papers use IDA Pro, Binary Ninja, or Ghidra. Different papers use different scripts to extract features, even when they use the same disassembler. When you try to compare results across papers, you’re comparing a whole non-standardized mess of a pipeline --- not to mention some people’s absolutely nasty research code, though I’m as guilty of that as anyone. The disassembler is load-bearing in ways that are invisible in the evaluation. It’s a “batteries not included” approach to function similarity, and it doesn’t do the core thing we expect science-by-empirical-observation to do: change one thing at a time. You can’t just say “let the best method be the best method,” because there’s no way to tell if the model is better or the disassembler. That’s not science.
Secondly, the same disassembler will be inconsistent across versions. Even if you commit to one disassembler, it changes, and not always for the better as far as your model is concerned. IDA ships major updates. Ghidra ships major updates. The analysis improves, and the disassembly changes ever so slightly. A state-of-the art model trained and evaluated against IDA 7.3 version can perform no better than random chance when using disassembly from IDA 8.4 on the exact same binaries. Ask me how I know. For any system you expect to be used as a benchmark against other methods for years, this is a disaster.
Both of these concerns are enough to shake most of the academic literature out there, but all of that says nothing about the problems when you actually try to use these systems.
Scaling is harder than it looks. When an analyst is already working on a binary they are almost certainly going to disassemble it anyway. The representation cost there is priced in. The problem is building the database. A useful known-function database means processing enormous numbers of binaries, possibly petabytes worth. Ignoring the fact that most disassemblers are built for interactive use, and can’t be used for scripting, let alone in parallel, the process is maddeningly slow. On the top-of-the-line hardware I was given when working in the IC, it took us minutes to disassemble each binary. Imagine trying to do a billion of them.
Worst of all, malware authors know you are disassembling their work. This one tends to get glossed over in academic settings, where the worst thing that can happen is that your model doesn’t sweep the competition, you can’t put the accuracy of your model in bold in every column of your results table, and a reviewer throws your paper in the garbage. Maybe try submitting it somewhere else? Better luck next time. You’ll get your ICML golden ticket eventually buddy.
In real deployments, malware analysis is the primary use case. Malware authors know this. They have known it for decades. They have built defenses accordingly. Instruction desynchronization. Self-modification at runtime. Overlapping instructions. These techniques do not need to defeat your similarity model. They just need to corrupt its input and feed it garbage. A system built on top of a disassembler inherits every single one its vulnerabilities, and it does so completely invisibly. This is fine for the specific binary that the analyst is looking at. They can discover pretty quickly that the disassembly is garbage. But remember what I said earlier about trust? The analyst can’t see every function in the database. They can’t know if there’s a perfect match out there your model is missing because it can’t handle garbage inputs. They’d better check everything by hand. Hey, why are we paying for this again?
The through-line here is that lifted representations only shift the complexity around. The model’s job might get scoped down, but only by handing the hard parts to a separate piece of software that you do not control, that changes without warning, that struggles at scale, and that your adversaries have had years to study. Examine that trade carefully before you make it.
In the next post I want to look at specific methods, what the evaluation literature actually measures versus what it claims to measure, and what a pipeline built on raw bytes actually looks like in practice.
—Noah